第一部分——安装conda
安装conda
mkdir tmp
cd tmp
sudo apt install curl
curl -O https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
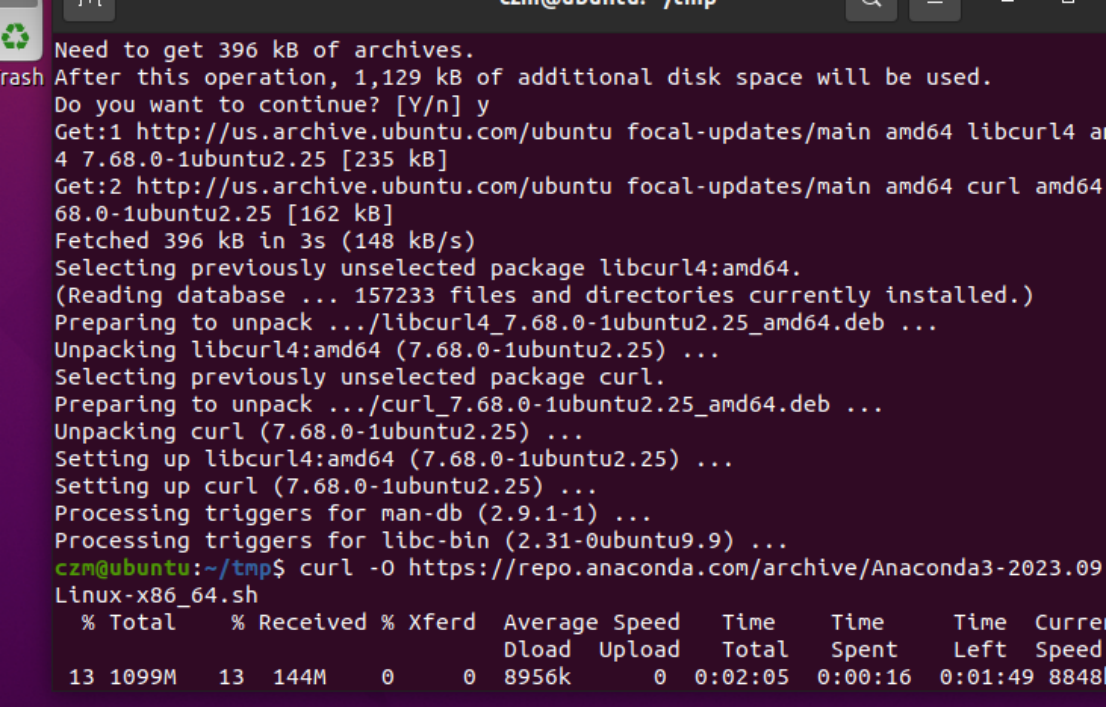
运行脚本bash Anaconda3-2023.09-0-Linux-x86_64.sh
一直enter
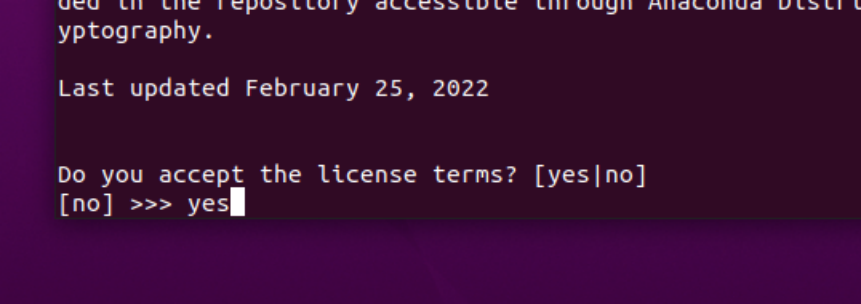
直接enter
安装程序提示用户接受默认位置或安装到其他位置。除非有特定需求,否则请使用默认路径。
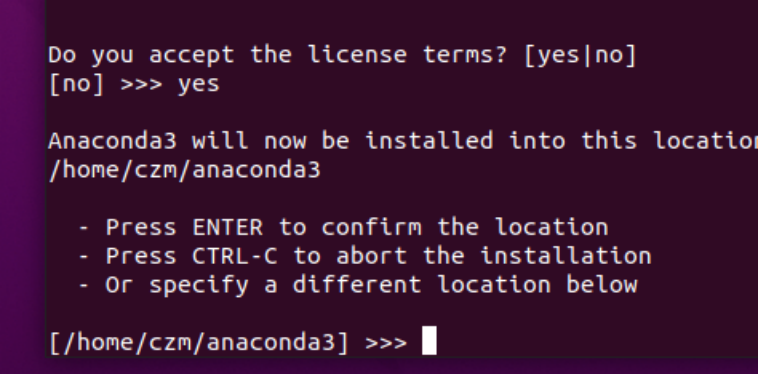
输入yes
安装完成并决定是否在启动时自动初始化 conda。除非你有特定的理由,否则在提示符后输入 yes。
 使用conda命令来测试安装
使用conda命令来测试安装
记得关掉命令行重新打开
输入conda info能显示出如下图的conda版本即为安装成功

更新conda包管理器
conda update conda
第二部分——配置和下载依赖
安装cmake
sudo apt install build-essential cmake
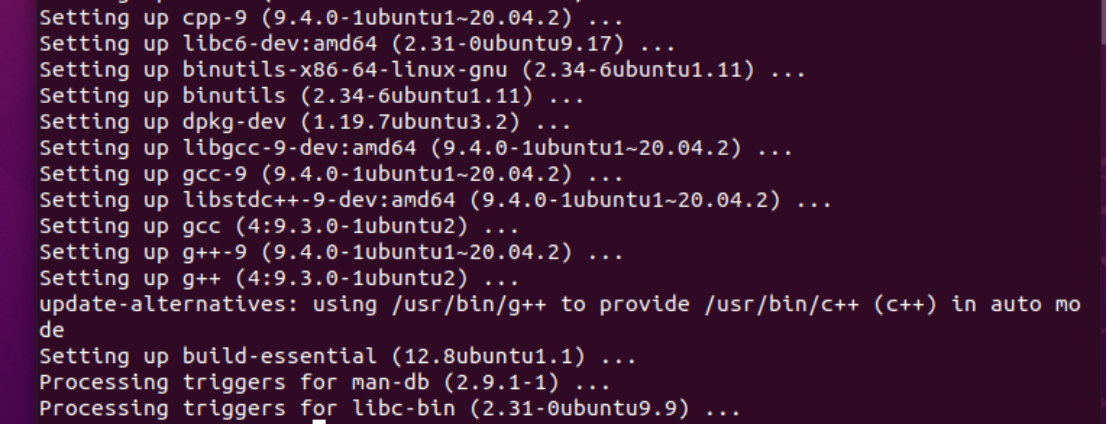
配置环境
sudo apt install git
git clone https://github.com/wenet-e2e/wenet.git
cd wenet
创造conda的环境并激活
conda create -n wenet python=3.8 (creat要空格-n)
激活wenet环境
conda activate wenet

下载必要的python模块
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
conda install pytorch=1.10.0 torchvision torchaudio=0.10.0 cudatoolkit=11.1 -cpytorch -c conda-forge
进入wenet的runtime/LibTorch目录
mkdir build && cd build && cmake .. && cmake --build .(.. && 以及build后面有 .)
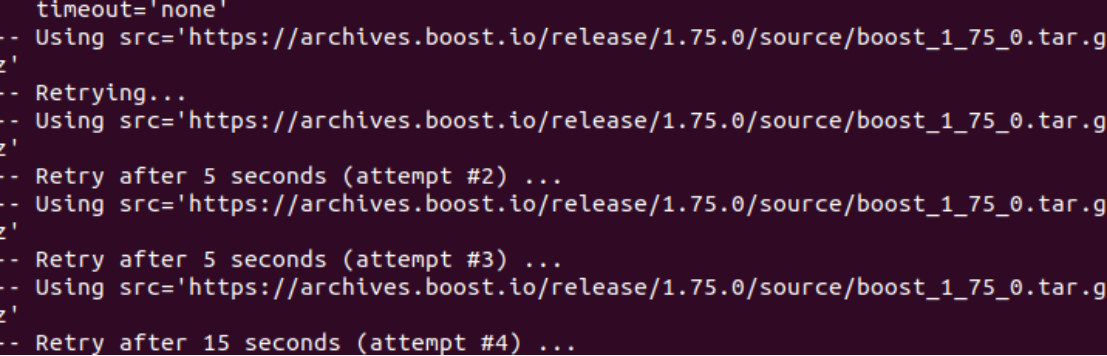 如果网络环境不好(如上图)就需要科学上网来手动下载
如果网络环境不好(如上图)就需要科学上网来手动下载

下好后 会在Downloads
如果是只读文件 需要切换到 cd /home/czm(你的用户名)/Downloads (或者右键打开命令行)开启权限
chmod -R 777 (文件名)
把刚刚下好的文件到这个目录里面

这时候要cd..返回上面那个界面,使用rm -r build命令把刚刚那个build目录删了,再重新安装。

接着要去魔搭社区下载两个文件
https://www.modelscope.cn/models/wenet/aishell2/files 点击模型文件

把这两个文件复制到build文件夹下面

用ffmpeg把wav音频转换成一个16k采样率,单通道,16bits的音频文件test.wav
命令:ffmpeg -i original.wav -ar 16000 -ac 1 -acodec pcm_s16le test.wav
并把test.wav放到libtorch目录中
第三部分———运行wenet
配置环境变量
export GLOG_logtostderr=1
export GLOG_v=2
wav_path=test.wav
model_dir=./build

然后运行wenet
./build/bin/decoder_main \
--chunk_size -1 \
--wav_path $wav_path \
--model_path $model_dir/final.zip \
--unit_path $model_dir/units.txt 2>&1 | tee log.txt
运行结果如下,使用的是非流式的识别,chunk_size设置为-1,但是不能实时对音频进行转写。
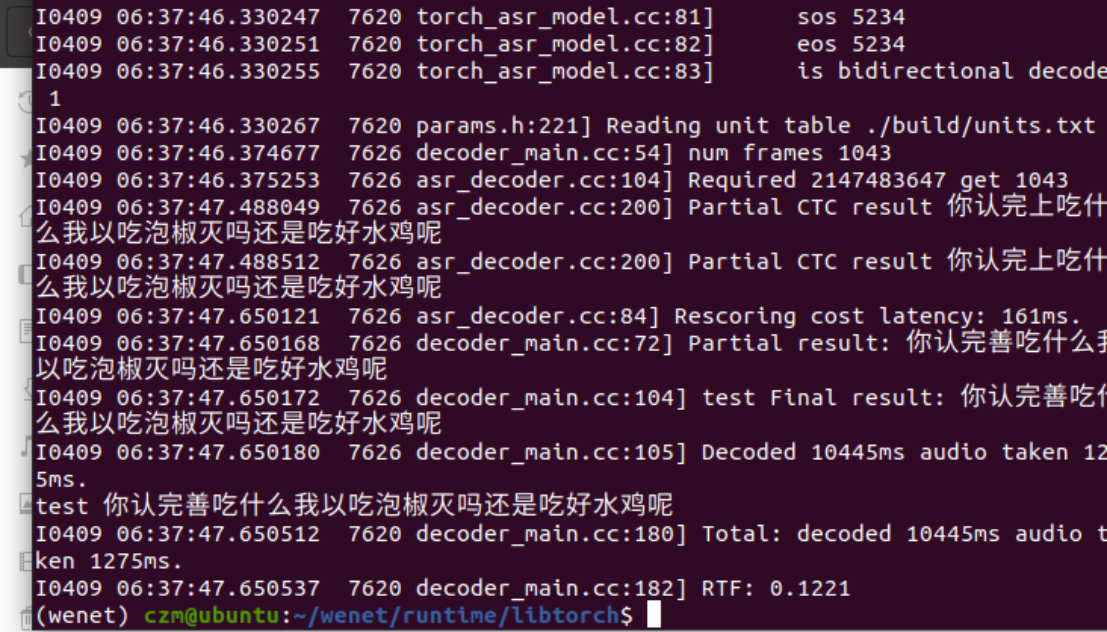
但是流式音频识别也是可以实现的,使用另外一组命令将识别的后端运行起来,打开index.html即可在前端调用模型文件进行实时语音转写。
执行如下指令,将 model_dir 设置为你的模型目录地址。
export GLOG_logtostderr=1
export GLOG_v=2
model_dir=./build
./build/bin/websocket_server_main \
--port 10086 \
--chunk_size 16 \
--model_path $model_dir/final.zip \
--unit_path $model_dir/units.txt 2>&1 | tee server.log